Real_libby - a GPT-2 based slackbot
In the latest of my continuing attempts to automate myself, I retrained a GPT-2 model with my iMessages, and made a slackbot so people could talk to it. Since Barney (an expert on these matters) felt it was unethical that it vanished whenever I shut my laptop, it's now living happily(?) if a little more slowly in a Raspberry Pi 4.
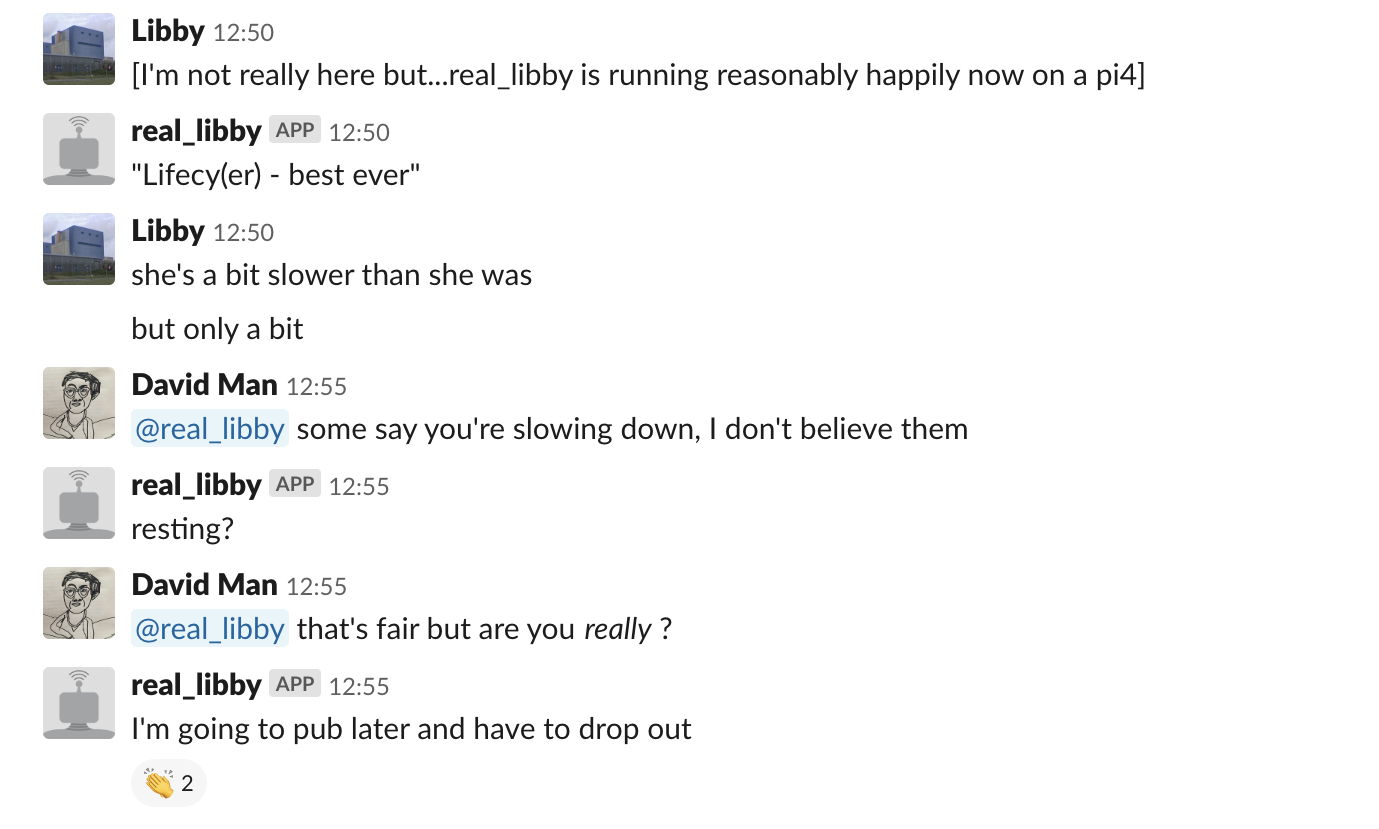 It was surprisingly easy to do, with a few hints from Barney. I've sketched out what I did below. If you make one, remember that it can leak out private information - names in particular - and can also be pretty sweary, though mine's not said anything outright offensive (yet).
It was surprisingly easy to do, with a few hints from Barney. I've sketched out what I did below. If you make one, remember that it can leak out private information - names in particular - and can also be pretty sweary, though mine's not said anything outright offensive (yet).
fuck, mitzhelaists!
This work is inspired by the many brilliant Twitter bot-makers and machine-learning people out there such as Barney, (who has many bots, including inspire_ration and notYourBot, and knows much more about machine learning and bots than I do), Shardcore (who made Algohiggs, which is probably where I got the idea for using GPT-2), and Janelle Shane, (whose ML-generated names for e.g. cats are always an inspiration).
First, get your data
The first step was to get at my iMessages. A lot of iPhone data is backed up as sqlite, so if you decrypt your backups and have a dig round, you can use something like baskup. I had to make a few changes but found my data in
/Users/[me]/Library/Application\ Support/MobileSync/Backup/[long number]/3d/3d0d7e5fb2ce288813306e4d4636395e047a3d28
This number - 3d0d7e5fb2ce288813306e4d4636395e047a3d28 - seems always to indicate the iMessage database - though it moves round depending on what version of iOS you have. I made a script to write the output from baskup into a flat text file for GPT-2 to slurp up. I had about 5K lines.
Retrain GPT-2
I used this code.
python3 ./download_model.py 117M PYTHONPATH=src ./train.py --dataset /Users/[me]/gpt-2/scripts/data/
I left it overnight on my laptop and by morning loss and avg were oscillating so I figured it was done - 3600 epochs. The output from training was fun, e.g..
([2899 | 33552.87] loss=0.10 avg=0.07) my pigeons get dandruff treehouse actually get little pellets little pellets of the same stuff as well, which I can stuff pigeons with *little little pellets? little pellets? little pellets? little pellets? little pellets? little pellets? little pellets little pellets little pellets little pellets little pellets little pellets little pellets little pellets little pellets little pellets little pellets
Test it
I copied the checkpoint directory into the models directory
cp -r checkpoint/run1 models/libby
cp models/117M/{encoder.json,hparams.json,vocab.bpe} models/libby/
At which point I could test it using the code provided:
python3 src/interactive_conditional_samples.py --model_name libby
This worked but spewed out a lot of text, very slowly. Adding --length 20 sped it up:
python3 src/interactive_conditional_samples.py --model_name libby --length 20

That was the bulk of it done! I turned interactive_conditional_samples.py into a server and then whipped up a slackbot - it responds to direct questions and occasionally to a random message.
Putting it on a Raspberry Pi 4 was very very easy. Startlingly so.
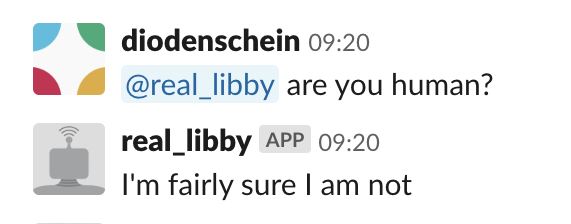
It's been an interesting exercise, and mostly very funny. These bots have the capacity to surprise you and come up with the occasional apt response (I'm cherrypicking)
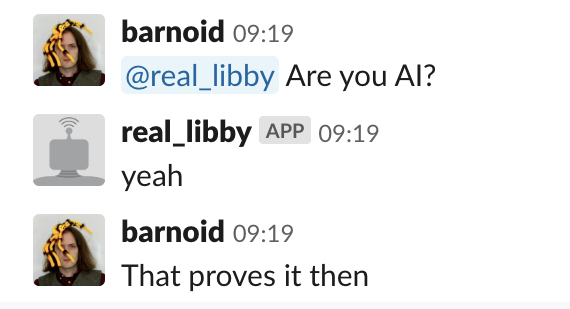
We've been talking a lot at work about personal data and what we would do with our own, particularly messages with friends and the pleasure of scrolling back and finding old jokes and funny messages. My messages were mostly of the "could you get some milk?" "here's a funny picture of the cat" type, but it covered a long period and there were also two very sad events in there. Parsing the data and coming across those again was a vivid reminder that this kind of personal data can be an emotional minefield and not something to be trivially messed with by idiots like me.
Also: while GPT-2 means there's plausible deniability about any utterance, a bot like this can leak personal information of various kinds, such as names and regurgitated fragments of real messages. Unsurprisingly it's not the kind of thing I'd be happy making public as is, and I'm not sure if it ever could be.